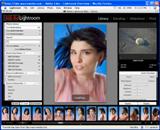
 アドビ(マクロメディア)が、1月8日にAdobe Labにおいて、プロ向けの写真整理・フィルタリング用ツール「Adobe Lightroom Beta」を公開したようだ。Lightroom Beta 1 Overview Videoという解説ビデオがあるのだけど、最初は「なんや、これ?写真整理ツールかいな」と思ったのだが、実はこれ、昨年10月20日にアップルが発表した、Apertureの競合なのだ。
アドビ(マクロメディア)が、1月8日にAdobe Labにおいて、プロ向けの写真整理・フィルタリング用ツール「Adobe Lightroom Beta」を公開したようだ。Lightroom Beta 1 Overview Videoという解説ビデオがあるのだけど、最初は「なんや、これ?写真整理ツールかいな」と思ったのだが、実はこれ、昨年10月20日にアップルが発表した、Apertureの競合なのだ。両者は必要なマシンスペックが異なっていて、PertureがDual 2.0GHzG5+2GBRAM、Lightroom が1GHzG4+768MBRAM(最近、Mac使ってないのでどれくらい違うのかわからん(汗))となっている模様。
デジカメが発達して便利になった分、素人でさえJPEGベースの写真データの管理に苦労する時代になった。ましてや、写真のプロというのは素人とは違って膨大な量の写真を撮るし、おまけに彼らはJPEGという(圧縮ロスが生じる)非可逆圧縮のフォーマットベースで写真を選別したりしない。それに500dpiとか600dpiとかそういう世界ではなくて、1200dpiとか2400dpiとかそういうの世界だろうから、1枚が数十MB(もっと?)にもなるんだろうしね。そら、選ぶだけでも大変なんだろうというのはなんとなくわかる。
プロ向けのソフトの話なのにここで取り上げた理由は「データ量」にある。個人だろうが企業だろうが、これから扱わねばならないデータは飛躍的に増えることは間違いない。Web2.0の真髄もAjaxとかのコードではなくてデータ!、とどんどん傾注していってる > 自分。オライリーが言ってる通りなんだけどね。
話は逸れますが、以前、データベース屋さんと意見が対立したことがありました。僕はOSとかそれに近い系のソフトウェア屋だったので「データが一番だ」「いや、コードだ」と今から考えると無益な争いをしてた(笑)。 僕はその人がスキーマの美しさ(正規化レベルとか)とかセマンティックとかACID(Atomicity,Consistency,Isolation,Durability)の保証みたいなところ、つまり「データベース」を前提にしてるのが気に入らなかったのだ。
でも今は間違ってたのは僕だと詫びないとあかんかもなあ。結局はデータを効率よく意図通りに扱ってもらうためにユーザーインターフェースの改善をしたり応答性を高めたりしてるわけでしょ? その武器はAjaxだの、ruby/ror(ruby on rail)だったりpythonだったりするとして。Taggingも然り。Windows Vistaで搭載されるはずだったWinFS(誤解を恐れずに言えば、ファイルシステムを丸ごとSQL Serverにしちゃうってことです)も然り。SQLで自分のDisk上のデータを探そうってわけですから、目的は似たようなもん。
でもねえ、それでもきっと手段は足りない。デジカメの写真整理はPicasaでやってますが全然だめ。最初に几帳面にネーミングするタイプでもないし(笑)わけわからん状態になりつつある。そのうち、大切なメールにとんでもない写真を添付してしまいそうでコワイ。だいたいね、人間なんて「間違う」もんだし「忘却する」ものなんやから(笑)
で、人間とデータ量の戦いは人間は勝てないだろうから、自立型のデータ(つまり、自律コードを含んだオブジェクト)みたいな話は当然出るわけですが、一方でこれからはITの世界もますます性悪説(Ethical view that human nature is basically evil)をベースに考えなければならないってことがある。真面目な話、いずれ「性悪説開発方法論」とか「性悪説設計入門」とか「性悪説に基づくテスト方法論」とか、果ては「性悪説2.0」という書籍が出る予感がするわ、ホント(笑)。 とにかく、全てのデータにコードが含まれているなんて恐い恐い。WebページのJavascriptは許せるとして、JPEGファイル自身にコードが仕込まれたらこわくてクリックできないって(笑) すると、やはり、Web3.0あたりではついにOntologyとAgent(代理人)を導入しないとダメじゃないか、と一瞬思えるんですけど、性悪説ハンドリングにはもうヒトヒネリ要るはず! Googleはどう考えているのだろう...。一言、「Do not evil!」とデータ先頭に含めるか?
なんかまとまってないな、また続編書くかも、です。
[Web2.0][IT][Adobe][テクノロジー][Technology][ajax]